
“walk beside you ”
前言
如果将梦想作为信仰,不放弃地追求下去,一定会梦想成真的。 —— 岸本齐史
正文
布隆过滤器(Bloom Filter)是1970年由布隆提出的。它实际上是一个很长的二进制向量和一系列随机映射函数。布隆过滤器可以用于检索一个元素是否在一个集合中。它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难。
基本概念
如果想要判断一个元素是不是在一个集合里,一般想到的是将所有元素保存起来,然后通过比较确定。链表,树等等数据结构都是这种思路. 但是随着集合中元素的增加,我们需要的存储空间越来越大,检索速度也越来越慢(O(n),O(logn))。不过世界上还有一种叫作散列表(又叫哈希表,Hash table)的数据结构。它可以通过一个Hash函数将一个元素映射成一个位阵列(Bit array)中的一个点。这样一来,我们只要看看这个点是不是1就可以知道集合中有没有它了。这就是布隆过滤器的基本思想。
Hash面临的问题就是冲突。假设Hash函数是良好的,如果我们的位阵列长度为m个点,那么如果我们想将冲突率降低到例如 1%, 这个散列表就只能容纳m / 100个元素。显然这就不叫空间效率了(Space-efficient)了。解决方法也简单,就是使用多个Hash,如果它们有一个说元素不在集合中,那肯定就不在。如果它们都说在,虽然也有一定可能性它们在说谎,不过直觉上判断这种事情的概率是比较低的。
优点
相比于其它的数据结构,布隆过滤器在空间和时间方面都有巨大的优势。布隆过滤器存储空间和插入/查询时间都是常数。另外, Hash函数相互之间没有关系,方便由硬件并行实现。布隆过滤器不需要存储元素本身,在某些对保密要求非常严格的场合有优势。 布隆过滤器可以表示全集,其它任何数据结构都不能。
缺点
但是布隆过滤器的缺点和优点一样明显。误算率是其中之一。随着存入的元素数量增加,误算率随之增加。常见的补救办法是建立一个小的白名单,存储那些可能被误判的元素。但是如果元素数量太少,则使用散列表足矣。 另外,一般情况下不能从布隆过滤器中删除元素。我们很容易想到把位列阵变成整数数组,每插入一个元素相应的计数器加1, 这样删除元素时将计数器减掉就可以了。然而要保证安全的删除元素并非如此简单。首先我们必须保证删除的元素的确在布隆过滤器里面. 这一点单凭这个过滤器是无法保证的。另外计数器回绕也会造成问题。 在降低误算率方面,有不少工作,使得出现了很多布隆过滤器的变种。
应用
网页URL的去重,垃圾邮件的判别,集合重复元素的判别,查询加速(比如基于key-value的存储系统)等。
实现
有一个长度为m的bit型数组,如我们所知,每个位置只占一个bit,每个位置只有0和1两种状态。假设一共有k个哈希函数相互独立,输入域都为s且都大于等于m,那么对同一个输入对象(可以想象为缓存中的一个key),经过k个哈希函数计算出来的结果也都是独立的。对算出来的每一个结果都对m取余,然后在bit数组上把相应的位置设置为1(描黑),如下图所示:
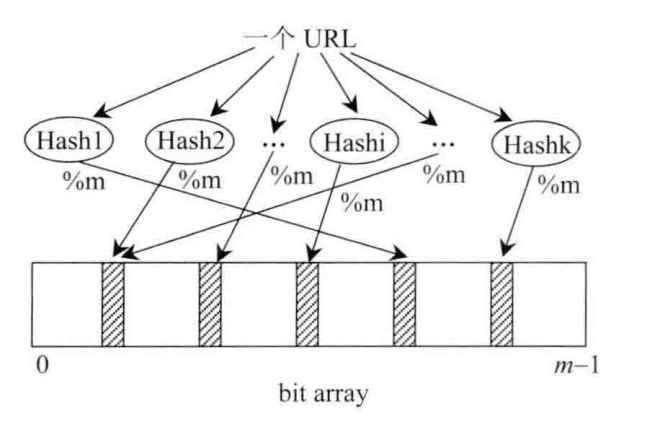
至此一个输入对象对bit array集合的影响过程就结束了,我们可以看到会有多个位置被描黑,也就是设置为1.接下来所有的输入对象都按照这种方式去描黑数组,最终一个布隆过滤器就生成了,它代表了所有输入对象组成的集合。
那么如何判断一个对象是否在过滤器中呢?假设一个输入对象为hash1,我们需要通过看k个哈希函数算出k个值,然后把k个值取余(%m),就得到了k个[0,m-1]的值。然后我们判断bit array上这k个值是否都为黑,如果有一个不为黑,那么肯定hash1肯定不在这个集合里。如果都为黑,则说明hash1在集合里,但有可能误判。因为当输入对象过多,而集合过小,会导致集合中大多位置都会被描黑,那么在检查hash1时,有可能hash1对应的k个位置正好被描黑了,然后错误的认为hash1存在集合里。
误判率
如果bit array集合的大小m相比于输入对象的个数过小,失误率就会变高。这里直接引入一个已经得到证明的公式,根据输入对象数量n和我们想要达到的误判率为p计算出布隆过滤器的大小m和哈希函数的个数k.
布隆过滤器的大小m公式:
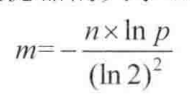
哈希函数的个数k公式:
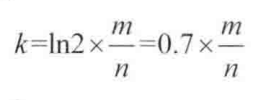
布隆过滤器真实失误率p公式:
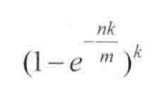
假设我们的缓存系统,key为userId,value为user。如果我们有10亿个用户,规定失误率不能超过0.01%,通过计算器计算可得m=19.17n,向上取整为20n,也就是需要200亿个bit,换算之后所需内存大小就是2.3G。通过第二个公式可计算出所需哈希函数k=14.因为在计算m的时候用了向上取整,所以真是的误判率绝对小于等于0.01%。
Googlel BloomFilter
- pom引入依赖
<dependency>
<groupId>com.google.guava</groupId>
<artifactId>guava</artifactId>
<version>25.1-jre</version>
</dependency>
- example
public static void main(String... args){
/**
* 创建一个插入对象为一亿,误报率为0.01%的布隆过滤器
*/
BloomFilter<CharSequence> bloomFilter = BloomFilter.create(Funnels.stringFunnel(Charset.forName("utf-8")), 100000000, 0.0001);
bloomFilter.put("121");
bloomFilter.put("122");
bloomFilter.put("123");
System.out.println(bloomFilter.mightContain("121"));
}